개인 정보보호 등을 위해 검색엔진이 긁어가는 것을 막는 법입니다.
① 위와 같이 하여 robots.txt 이름으로 저장합니다.
위 내용을 설명하자면 모든 검색엔진이 긁어가는 것을 막는 겁니다.
User-agent: * *은 모든 검색엔진을 뜻함.
Disallow: / /는 모든 디렉토리
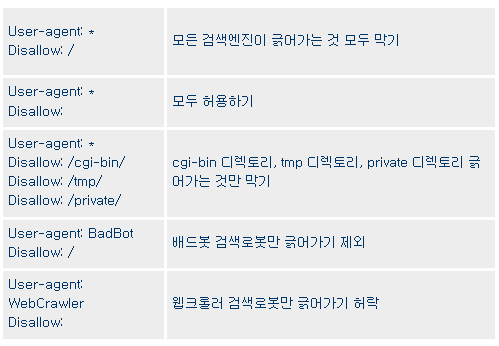
[ robots.txt 상세 옵션 설명]
② robots.txt 파일을 ftp로 올립니다. 최상위 디렉토리에 올려야합니다.
예) http://www.servis.co.kr/robots.txt ( O )
http://www.servis.co.kr/test/robots.txt ( X )
* robots.txt 유의사항
1. 사이트는 하나의 “robots.txt” 만을 가질 수 있다
2. “robots.txt” 문자열은 모두 소문자이어야 하며, 공백은 허용 되지 않는다.
3. 최상위 디렉토리의 robots.txt만 읽는다. (다른 디렉토리의 robots.txt는 아무소용이없다)
이 방법 외에도 html 페이지에 메타 태그를 써서 검색엔진을 막을 수 있습니다.
<meta name=”robots” content=”noindex,nofollow”>
위 소스를 와 사이에 넣어주면 됩니다.
유의할 점은 위와 같은 방법이 모든 검색엔진을 완전 차단하진 못한다는 걸 염두해두세요.
자세한 사항은 http://www.robotstxt.org/ 참고하시길 바랍니다.